
Les applications modernes doivent fonctionner de manière transparente sur des plateformes comme iOS, Android et le web. Mais la synchronisation des données entre ces systèmes est délicate. Voici pourquoi :
Des plateformes comme Adalo, un créateur d'applications sans code pour les applications web basées sur des bases de données et les applications iOS et Android natives—une seule version sur les trois plateformes, publiée sur l'App Store Apple et Google Play, contribue à résoudre ces défis en fournissant une gestion de données unifiée sur les appareils à partir d'un seul environnement de développement.
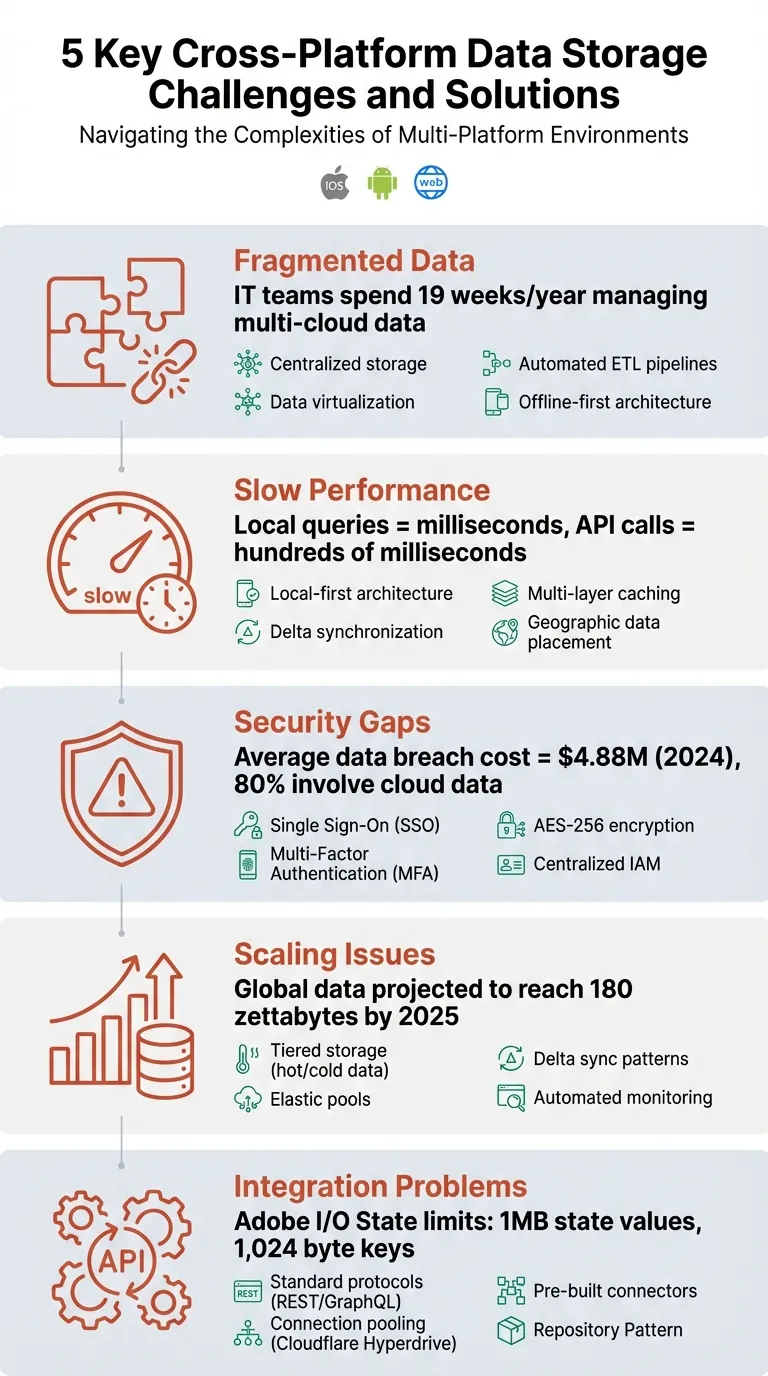
- Données fragmentées: Les systèmes déconnectés créent des silos, ce qui rend difficile la synchronisation des informations.
- Performance lente: Les délais réseau et les méthodes de synchronisation inefficaces frustrent les utilisateurs.
- Lacunes en matière de sécurité: Les mesures incohérentes entre les plateformes augmentent les risques.
- Problèmes d'évolutivité: La croissance des demandes de données peut surcharger l'infrastructure.
- Problèmes d'intégration: Les problèmes de compatibilité entre les systèmes ralentissent le développement.
Solutions incluent les architectures locales d'abord, les modèles de synchronisation delta, les protocoles de sécurité unifiés et les stratégies de stockage évolutives. Ces approches garantissent des synchronisations plus rapides, une meilleure sécurité et des opérations multiplateforme plus fluides.
5 défis clés du stockage de données multiplateforme et solutions
Défi 1 : données fragmentées et systèmes déconnectés
Que sont les silos de données
Les données fragmentées sur les plateformes créent un obstacle majeur à la synchronisation transparente. Les silos de données apparaissent lorsque différents départements ou plateformes stockent des informations sans les relier ensemble. Par exemple, votre équipe de vente peut s'appuyer sur une base de données, votre application mobile sur une autre, et votre plateforme web sur une troisième - ce qui nécessite une rapprochement manuel pour aligner les données.
Les systèmes existants ne s'intègrent souvent pas aux outils modernes basés sur le cloud, laissant derrière eux des pools de données isolés. Les fusions peuvent aggraver le problème en réunissant des bases de données avec des structures incompatibles. Pendant ce temps, les départements gérant leurs données indépendamment amplifient la fragmentation. Dans des secteurs comme la santé, ces données déconnectées peuvent coûter des dizaines à des centaines de milliards de dollars annuellement, tandis que les équipes informatiques consacrent en moyenne 19 semaines chaque année à gérer les données dans plusieurs environnements de cloud public.
Solutions : connecter vos données
Briser ces silos commence par l'intégration de données provenant de diverses sources dans un système unifié. Une approche efficace consiste à adopter des architectures de stockage centralisées, qui créent une source unique de vérité. Les lacs de données sont idéaux pour consolider les données brutes et non structurées provenant de plusieurs sources, tandis que les entrepôts de données sont mieux adaptés à la gestion des données structurées utilisées dans des analyses spécifiques. Pour plus de flexibilité, les entrepôts de données combinent les forces des deux, permettant la gestion des données structurées et non structurées dans un seul système.
Une autre solution est la virtualisation des données. Des outils comme Denodo et Données de matériel Cisco vous permettent d'accéder à une vue unifiée des données sur des plateformes comme soutenue par AWS, Azure, et Google Cloud sans déplacer physiquement les données. Ceci est particulièrement utile pour l'analyse en temps réel lorsqu'il est nécessaire de maintenir les données à leur emplacement d'origine.
Pour les organisations prêtes à consolider, les pipelines ETL automatisés simplifient le processus. Des outils tels que Talend ou Stitch Data peuvent déplacer et transformer les données des systèmes disparates dans un entrepôt centralisé. Le stockage des données dans des formats interopérables comme Apache Parquet ou Avro assure la compatibilité avec les outils d'analyse et les plateformes cloud.
Les applications multiplateforme peuvent bénéficier considérablement des architectures locales d'abord, qui mettent en cache les données localement et les synchronisent avec le cloud lorsque la connectivité est rétablie. Cela garantit que les utilisateurs ont accès aux informations même dans des conditions réseau médiocres, améliorant la synchronisation des données sur les plateformes iOS, Android et web simultanément.
Défi 2 : performance lente et délais
Qu'est-ce qui cause les délais multiplateforme
Lorsque les systèmes sont fragmentés, garantir des transferts de données rapides est essentiel pour éviter une performance multiplateforme lente. Un coupable majeur derrière les délais est les modèles de données dépendants du serveur, qui exigent que les applications attendent les réponses du serveur avant d'afficher les informations. Bien que les requêtes locales puissent être complétées en seulement quelques millisecondes, les appels réseau peuvent en prendre des centaines - surtout lorsque les serveurs sont situés loin des utilisateurs ou lorsque les conditions réseau sont mauvaises. L'architecte mobile Sudhir Mangla décrit ce scénario frustrant comme « Lie-Fi » - des situations où les appareils indiquent un signal fort mais souffrent d'un débit faible, de pics de latence imprévisibles ou de requêtes perdues.
Les méthodes de synchronisation inefficaces jouent également un rôle. Les approches de synchronisation complète, par exemple, abandonnent souvent les données locales pour recharger des ensembles de données entiers, gaspillant du temps et des ressources. De même, les limites de débit des API tierces peuvent forcer plusieurs cycles pour importer de grands ensembles de données, ralentissant davantage les choses.
« Même lorsque le réseau est puissant, la récupération locale de données est toujours plus rapide qu'un aller-retour vers le serveur. Une requête sur une base de données sur l'appareil peut retourner les résultats en millisecondes ; un appel API peut prendre des centaines. » - Sudhir Mangla, Mobile Architect
« L'approche hors ligne en premier n'est donc pas seulement une stratégie de résilience - c'est une stratégie de performance. »
Ces défis soulignent la nécessité de repenser comment les données sont transférées et gérées.
Solutions : Transfert de données plus rapide
Une combinaison de architecture locale en priorité et la synchronisation delta peut améliorer considérablement les performances. En utilisant une base de données sur l'appareil - comme Room, Realm, ou SQLite - comme magasin de données principal, les applications peuvent gérer les interactions de l'interface utilisateur instantanément. Un moteur de synchronisation en arrière-plan peut ensuite gérer les mises à jour des données, en échangeant uniquement les enregistrements qui ont changé à l'aide de jetons de synchronisation pilotés par le serveur pour éviter les problèmes de désynchronisation d'horloge.
Pour améliorer davantage la vitesse, implémentez la mise en cache multicouche pour les réponses API, les requêtes de base de données et les actifs statiques, en veillant à ce que les données fréquemment consultées soient récupérées rapidement. Placez les magasins de données dans la même région géographique que vos composants d'application pour réduire la latence et éviter les frais de bande passante supplémentaires entre régions. Les gestionnaires de tâches en arrière-plan peuvent gérer les processus de synchronisation sans interrompre les interactions utilisateur, tandis que les mises à jour optimistes permettent à l'interface utilisateur de refléter les modifications immédiatement, en synchronisant en arrière-plan pour finaliser les mises à jour.
Ces stratégies ne règlent pas seulement les retards, mais créent également une expérience utilisateur plus fluide et plus réactive.
Défi 3 : Problèmes de sécurité et de contrôle d'accès
Risques de sécurité incohérente
Lorsque les pratiques de sécurité diffèrent selon les plates-formes comme iOS, Android et le web, des vulnérabilités émergent. En 2026, le coût moyen d'une violation de données a atteint 4,88 millions de dollars, environ 80 % des violations étant liées aux données stockées dans le cloud. Cela souligne les risques commerciaux sérieux des mesures de sécurité incohérentes.
L'une des préoccupations majeures est la fuite de données entre locataires dans les infrastructures partagées. Sans une authentification et une autorisation fortes en place, il est possible pour un locataire d'accéder par inadvertance aux données d'un autre dans des bases de données partagées ou des conteneurs blob. Ajoutant au problème, les fournisseurs de cloud utilisent souvent des paramètres par défaut et des protocoles de chiffrement différents, créant des points faibles que les attaquants peuvent exploiter. Les processus manuels, comme le suivi des modifications de schéma ou l'application de correctifs sur plusieurs bases de données, augmentent encore les risques d'erreur humaine et de lacunes en matière de sécurité.
Un autre défi réside dans la mise en œuvre de contrôles granulaires comme la sécurité au niveau des lignes. Sans une conception et des tests appropriés, ces contrôles peuvent laisser des lacunes exploitables. Dans les systèmes de réplication asynchrone, les mises à jour simultanées entre les emplacements peuvent entraîner des états de données incohérents, contournant potentiellement les contraintes de sécurité si la résolution des conflits n'est pas correctement gérée.
La solution ? Une stratégie de sécurité unifiée qui fonctionne de manière transparente sur toutes les plates-formes.
Solutions : Systèmes de sécurité unifiés
Pour relever ces défis, une approche consolidée de la sécurité est essentielle. Commencez par d'authentification unique (SSO) l'utilisation de protocoles comme OAuth 2.0 ou SAML. Cela assure des politiques de sécurité cohérentes sur toutes les plates-formes - qu'il s'agisse d'iOS, Android ou du web. Associez cela à une gestion centralisée des identités et des accès (IAM) pour appliquer le Principe du Moindre Privilège, limitant l'accès des utilisateurs à uniquement ce qui est nécessaire pour leurs rôles.
l'authentification multifacteur (MFA) est une autre couche critique de défense. Avec l'hameçonnage et les identifiants volés étant les principales méthodes d'attaque en 2026, l'authentification multifacteur réduit considérablement le risque. Combinez cela avec des protocoles de chiffrement standardisés, comme AES-256 pour les données au repos et TLS pour les données en transit, pour établir une protection robuste dans votre infrastructure.
Voici comment une approche unifiée simplifie la sécurité :
| Fonctionnalité de sécurité | Défi spécifique à la plate-forme | Avantage unifié |
|---|---|---|
| Authentification | Différentes API biométriques (FaceID vs. Biométrie Android) | L'authentification multifacteur/SSO centralisée assure une expérience de connexion cohérente |
| Contrôle d'accès | Gestion des permissions incohérente selon les versions du système d'exploitation | Le contrôle d'accès basé sur les rôles (RBAC) standardise les permissions sur tous les appareils |
| Gestion des sessions | Stockage de jetons variable (Keychain vs. Keystore) | La gestion centralisée des jetons simplifie la logique d'expiration et d'actualisation |
| Stockage des données | Normes de chiffrement différentes selon la plate-forme | Le chiffrement standardisé (AES-256) sécurise les données sur toutes les plates-formes |
Pour une sécurité encore plus grande, envisagez le chiffrement au niveau du locataire en utilisant des outils comme « Always Encrypted » ou des clés gérées par le client (CMK). Ceux-ci assurent que les données restent protégées même dans les environnements de stockage partagés. Le motif Valet Key est une autre méthode efficace, offrant un accès sécurisé et limité dans le temps aux ressources de stockage sur plusieurs plateformes. De plus, stocker les identifiants sensibles et les clés API dans des outils de gestion des secrets dédiés - plutôt que de les coder en dur - fournit une couche de protection supplémentaire.
L'automatisation est essentielle pour réduire les erreurs humaines. Automatisez les modifications de schéma, les configurations de sécurité et les audits IAM réguliers pour maintenir une posture de sécurité solide. Pour la communication inter-plateformes, utilisez TLS mutuel (mTLS) certificats pour authentifier les services et assurer un transfert de données sécurisé dans les environnements cloud.
Défi 4 : Mise à l'échelle et gestion des coûts
Comment la croissance des données affecte l'infrastructure
Les données croissent à un rythme vertigineux. D'ici 2026, les données mondiales devraient atteindre 180 zettaoctets, avec de nombreux systèmes modernes générant des téraoctets - voire des pétaoctets - chaque jour. Pour les applications inter-plateformes, cette augmentation des données provient de deux sources : les données croissantes générées par client et une base de clients en constante expansion.
Gérer cette explosion de données n'est pas simple. Les bases de données traditionnelles ont souvent du mal à suivre une telle ampleur. Dans les configurations d'infrastructure partagée, le problème du « voisin bruyant » - où l'utilisation intensive d'un locataire dégrade les performances pour tout le monde - peut compliquer encore les choses. Une fois que vous gérez 50 locataires ou plus, la surveillance manuelle devient pratiquement impossible, rendant les outils de mise à l'échelle automatisée indispensables.
« Traitez les données comme l'atout le plus précieux de votre solution. En tant que fournisseur de logiciels indépendant (ISV), vous êtes responsable de la gestion des données de vos clients. Votre stratégie de conception de données et le choix de votre magasin de données peuvent affecter considérablement vos clients. »
– Cadre Well-Architected d'Azure Microsoft
Sans un plan solide, vous risquez soit le surprovisionnement - gaspillage d'argent sur des ressources inutilisées - soit le sous-provisionnement, qui entraîne des demandes limitées et des utilisateurs frustrés. Dans les environnements multi-locataires, les comptes de stockage qui dépassent leurs limites d'opérations par seconde peuvent commencer à rejeter les demandes, perturbant le service pour tous les utilisateurs.
Pour aborder efficacement ces défis, une approche stratégique est nécessaire, équilibrant la performance et l'efficacité des coûts.
Solutions : stockage hiérarchisé et contrôle des coûts
Pour gérer les volumes de données croissants sans exploser votre budget, vous avez besoin d'une combinaison de stratégies intelligentes. En s'appuyant sur les mesures de performance et de sécurité discutées précédemment, le contrôle des coûts devient la pièce finale pour des opérations transparentes inter-plateformes.
Commencez par aligner votre approche de stockage avec les modèles d'utilisation réels. Le stockage hiérarchisé est un excellent moyen d'optimiser les coûts. Les données « chaudes » fréquemment consultées peuvent rester sur des SSD haute performance, tandis que les données moins utilisées sont transférées vers des options plus abordables comme le stockage d'objets ou les niveaux d'archivage. Cette méthode réduit considérablement les dépenses tout en maintenant la vitesse pour les utilisateurs actifs.
La planification de la capacité est une autre étape critique. L'utilisation d'un modèle de « tailles de t-shirt » - classant les clients comme petits, moyens ou grands - aide à prédire les besoins en ressources et à les aligner sur les structures de facturation appropriées. Combinez cela avec la gestion du cycle de vie des données, qui automatise la rétention des données. Par exemple, des bases de données comme Azure Cosmos DB offrent des fonctionnalités Time-to-Live (TTL) pour supprimer automatiquement les enregistrements obsolètes, en maintenant votre base de données principale simplifiée.
Pour les charges de travail avec des pics imprévisibles, les pools élastiques et les modèles de débit partagé permettent à plusieurs bases de données de partager un seul pool de ressources. Les modèles sans serveur, qui se mettent à l'échelle automatiquement en fonction de la demande, sont une autre option, bien qu'ils puissent devenir moins rentables à mesure que l'utilisation augmente.
Pour réduire davantage les coûts dans les configurations multi-locataires, adoptez les modèles de synchronisation delta. Ceux-ci réduisent la bande passante et les demandes de serveur en synchronisant uniquement les modifications au lieu de l'ensemble des données. Par exemple, Cloudflare's D1 SQL database uses smaller, 10GB databases organized by user or tenant to scale efficiently.
La surveillance est également essentielle. Surveillez l'étranglement en suivant les opérations de stockage rejetées pour assurer que les comptes partagés restent dans leurs limites. L'automatisation de tâches comme la reconstruction d'index et le rééquilibrage de partitions peut également réduire le besoin d'intervention manuelle, économisant ainsi du temps et de l'argent.
| Stratégie | Idéal pour | Impact sur les coûts |
|---|---|---|
| Pools élastiques | Petites/moyennes bases de données avec pics de demande variables | Haute efficacité ; réduit les coûts des ressources inactives |
| Sans serveur | Nouvelles applications ou charges de travail imprévisibles et peu fréquentes | Paiement à l'usage ; peut devenir coûteux à plus grande échelle |
| Stockage d'archivage | Conformité à long terme et données historiques | Coût le plus bas ; temps de récupération plus lents |
| Synchronisation delta | Applications mobiles/inter-plateformes | Réduit les dépenses de bande passante et de serveur |
Défi 5 : Problèmes d'intégration et de compatibilité
Barrières d'intégration courantes
La liaison des systèmes de stockage entre les plateformes n'est pas aussi simple qu'il n'y paraît. L'un des principaux obstacles est l'incompatibilité des bibliothèques, qui force souvent les développeurs à maintenir des bases de code séparées pour les applications mobiles et web. Même lorsque les systèmes partagent la même structure de données, les incohérences dans la façon dont les différents systèmes d'exploitation et les navigateurs gèrent JSON peuvent entraîner un comportement imprévisible des applications.
Un autre défi est la latence de connexion, particulièrement dans les environnements sans serveur. Les bases de données SQL traditionnelles dépendent des sockets TCP, qui nécessitent plusieurs allers-retours pour établir des connexions sécurisées. Dans les configurations sans serveur ou informatique en bordure, ces connexions doivent être rétablies à chaque invocation, ajoutant des délais perceptibles. Ce problème est encore aggravé par la distance géographique - les serveurs basés aux États-Unis, par exemple, peuvent introduire une latence pour les utilisateurs d'autres parties du monde.
Les solutions de stockage natives du cloud apportent leurs propres limitations. Par exemple, les simples magasins clé-valeur comme Adobe I/O State manquent de fonctionnalités essentielles de requête telles que le filtrage de lignes, la sélection de colonnes spécifiques ou la limitation des résultats. Les développeurs habitués aux bases de données traditionnelles regrettent souvent ces capacités. De plus, Adobe I/O State restreint les valeurs d'état à 1 Mo et les tailles de clés à 1 024 octets, ce qui peut être restrictif pour certains cas d'usage. Ces défis mettent en lumière le besoin pressant de protocoles standardisés pour simplifier l'intégration multi-plateforme.
Solutions : Protocoles standardisés et connecteurs prêts à l'emploi
Les protocoles standardisés et les plateformes avec des connecteurs intégrés offrent un moyen pratique de relever les défis d'intégration. Des outils comme Cloudflare Hyperdrive résolvent les problèmes de latence en regroupant les connexions aux bases de données au niveau mondial, éliminant les délais causés par les poignées de main TCP répétées. Pour les systèmes sans connecteurs natifs, REST APIs ou les interfaces GraphQL fournissent un pont, permettant la compatibilité entre les plateformes. Pendant ce temps, des outils comme Adobe I/O State offrent des abstractions JavaScript en plus des bases de données distribuées, permettant aux développeurs de gérer la persistance de l'état sans se plonger dans des configurations cloud complexes.
Des plateformes comme Adalo simplifient encore l'intégration en offrant des connecteurs prédéfinis pour les services tiers populaires, y compris Airtable, Google Sheets, MS SQL Server, et PostgreSQL. Ces intégrations prêtes à l'emploi réduisent le besoin de codage backend extensif. Pour les systèmes hérités sans API, Adalo Blue tire parti de DreamFactory pour rationaliser les connexions.
Une autre approche efficace est le motif de dépôt, qui crée une limite claire entre la couche d'interface utilisateur et la couche de stockage. Cette abstraction masque si les données sont stockées localement (par exemple, SQLite ou Realm) ou à distance via les API cloud, ce qui facilite la maintenance du code multi-plateforme. Les développeurs peuvent également utiliser des extensions de fichiers spécifiques à la plateforme comme index.web.js et index.ios.js pour s'assurer que le code correct s'exécute sur chaque plateforme automatiquement. Pour améliorer la sécurité, protégez toujours les informations d'identification sensibles telles que les clés API et les mots de passe de base de données avec les secrets d'environnement. Des outils comme les secrets Wrangler vous permettent d'injecter en toute sécurité ces informations d'identification au moment de l'exécution.
Apprenez à créer des applications cross-plateforme avec stockage de données en ligne-hors ligne en moins de 30 minutes
Comment implémenter ces solutions
Résoudre les défis du stockage de données multi-plateforme nécessite une approche bien réfléchie. Voici comment vous pouvez mettre ces solutions en pratique.
Décomposer les grandes migrations
Lors du déplacement de données, le faire étape par étape est le choix le plus judicieux. Au lieu de tout déplacer à la fois, envisagez la migration échelonnée - aussi appelée migration goutte à goutte. Cette méthode transfère les données par petits lots, permettant aux anciens et nouveaux systèmes de fonctionner côte à côte. L'avantage ? Un temps d'arrêt minimal et des tests continus, ce qui la rend idéale pour les systèmes critiques. Par exemple, une entreprise a réussi la transition de son système de paiement en temps réel sans interruption en suivant cette approche.
Une autre option est la stratégie de migration en parallèle, où les deux systèmes fonctionnent simultanément avec une synchronisation en place. Le trafic n'est redirigé vers le nouveau système qu'une fois qu'il a été minutieusement testé et validé. Les deux stratégies évitent les risques d'une migration « au coup pour coup », qui pourrait entraîner un temps d'arrêt prolongé ou des défaillances majeures en cas de problème.
Après avoir complété la migration, une surveillance continue est essentielle pour maintenir les performances et assurer la stabilité.
Surveillance et amélioration des systèmes de données
Une fois que votre stockage multi-plateforme est opérationnel, surveiller ses performances est indispensable. Utilisez des mesures comme octets par seconde (o/s) ou transactions par seconde (TPS) pour suivre la performance du système. Même de petits changements aux requêtes peuvent avoir un effet perceptible sur la vitesse, il est donc crucial d'effectuer régulièrement des évaluations de performances. La surveillance du débit aide à identifier les goulots d'étranglement avant qu'ils n'affectent les utilisateurs.
« Chaque fois que votre application interroge la base de données... les performances de l'application en souffriront. Par conséquent, il est essentiel de toujours garder les performances à l'esprit lors de la construction. » - Ressources Adalo
L'automatisation des tâches routinières peut économiser du temps et améliorer la santé du système. Les tâches comme la reconstruction d'index, le rééquilibrage des partitions et la surveillance du volume de données doivent être automatisées partout où possible. Surveillez l'accélération et affinez régulièrement les performances pour que tout fonctionne correctement.
Lorsque votre base d'utilisateurs et vos données augmentent, une plateforme évolutive devient essentielle pour maintenir des performances constantes.
Utilisation de plateformes évolutives
Une plateforme construite sur une base de code unique peut simplifier considérablement la maintenance multi-plateforme. Adalo, par exemple, utilise une architecture à base de code unique qui rationalise le développement des applications mobiles et web. Les mises à jour effectuées une fois sont automatiquement appliquées sur les plateformes iOS, Android et web.
Cette approche unifiée non seulement réduit la fragmentation, mais accélère également le déploiement. Les équipes peuvent lancer des applications prêtes pour la production en quelques jours ou semaines, par rapport aux mois généralement nécessaires pour les solutions construites sur mesure.
Conclusion
La gestion du stockage de données multi-plateforme s'accompagne de son lot de défis - systèmes fragmentés, ralentissements de performances, vulnérabilités de sécurité et problèmes d'évolutivité. Résoudre ces problèmes nécessite des solutions unifiées qui sont bien planifiées, sécurisées et capables de croître avec vos besoins.
Les leaders du secteur soulignent régulièrement l'importance des données dans toute solution :
« Les données sont souvent considérées comme la partie la plus précieuse d'une solution car elles représentent vos informations commerciales précieuses et celles de vos clients. »
– John Downs, Ingénieur logiciel principal, Microsoft
Lors de la gestion des opérations pour des dizaines de locataires, l'automatisation devient un outil non négociable. Elle permet une croissance transparente sans heurter les limites de capacité. Comme l'explore cet article, le succès réside dans l'adoption d'une stratégie unifiée - une stratégie qui intègre le développement, le déploiement et la sécurité dans un cadre cohérent. Traitez vos données comme votre atout le plus critique en tirant parti des services gérés, des méthodologies standardisées et des architectures avec base de code unique pour réduire les risques et maintenir des performances cohérentes sur les plateformes. Des étapes comme les migrations progressives, la surveillance active et la maintenance automatisée assurent une base solide pour des opérations efficaces et évolutives.
Articles de blog connexes
- Synchronisation hors ligne par rapport à temps réel : gestion des conflits de données
- Synchronisation basée sur les événements pour les applications offline-first
- Comment synchroniser les données entre les applications web et mobiles
- Synchronisation ERP en temps réel avec les systèmes hérités
FAQ
Comment une architecture locale en priorité améliore-t-elle la synchronisation des données entre plateformes ?
Une architecture locale en priorité se concentre sur le stockage et le traitement des données directement sur l'appareil de l'utilisateur, offrant une expérience transparente même en l'absence de connexion Internet. Cette approche garantit que les utilisateurs peuvent accéder aux informations et les mettre à jour sans interruptions, ce qui est particulièrement utile dans les zones à connectivité réseau faible ou peu fiable. De plus, en traitant la plupart des opérations sur l'appareil, les applications deviennent plus réactives, avec des délais réduits causés par la communication avec le serveur.
Lorsque la connexion est rétablie, le système synchronise automatiquement les modifications apportées localement avec les bases de données distantes, en maintenant la cohérence des données sur les appareils et les plateformes. Ce processus de synchronisation inclut souvent la détection et la résolution des conflits pour maintenir l'exactitude des données. En synchronisant uniquement lorsque cela est nécessaire, l'architecture locale en priorité économise les ressources réseau, allège la charge du serveur et se met à l'échelle efficacement. Cela en fait un choix judicieux pour les applications conçues pour être utilisées sur plusieurs appareils, offrant une expérience plus rapide et plus fiable dans des conditions réseau moins qu'idéales.
Quels sont les meilleurs moyens de sécuriser les données sur différentes plateformes ?
Sécuriser les données sur différentes plateformes nécessite un mélange de stratégies pour les garder à la fois sûres et accessibles. Une étape clé est le chiffrement des données au repos et en transit. Cela garantit que les informations sensibles restent protégées, en particulier lorsqu'elles sont transférées entre les plateformes ou les environnements cloud.
Une autre mesure critique consiste à établir des contrôles d'accès robustes. Des outils comme d'authentification unique (SSO) et les autorisations basées sur les rôles restreignent l'accès à ceux qui sont autorisés uniquement. Associez-les à des protocoles d'authentification sécurisés et à des systèmes de gestion des identités pour ajouter une couche de protection supplémentaire.
Pour améliorer à la fois la sécurité et les performances, affinez la façon dont les données sont gérées. Rationalisez les requêtes, utilisez la mise en cache pour réduire les temps de chargement et adoptez des modèles de synchronisation hors ligne en priorité pour assurer la cohérence des données même dans des conditions réseau peu fiables. Ces étapes non seulement améliorent l'expérience utilisateur, mais minimisent également les risques potentiels liés aux données obsolètes ou non synchronisées. Ensemble, ces stratégies créent un cadre robuste pour protéger les données sur les plateformes.
Qu'est-ce que le stockage échelonné et comment réduit-il les coûts dans le stockage de données entre plateformes ?
Le stockage échelonné offre un moyen judicieux de gérer les données sur les plateformes en les organisant en fonction de la fréquence d'accès. Les données fréquemment consultées sont conservées sur un stockage haut de gamme à haut débit, tandis que les données moins utilisées sont transférées vers des options plus lentes et économiques.
Cette méthode crée un équilibre entre la performance et le coût. Elle garantit que les tâches critiques fonctionnent correctement tout en maintenant les dépenses de stockage gérables. En adaptant les solutions de stockage à l'utilisation des données, les entreprises peuvent économiser de l'argent sans compromettre l'efficacité ou le potentiel de croissance.
Créez votre application rapidement avec l'un de nos modèles d'application prédéfinis
Commencez à créer sans codeContenu connexe
Liste de contrôle pour les tests d'applications multiplate-forme
Liste de contrôle pour les tests d'applications multiplate-forme
Une liste de contrôle pratique pour tester des applications multiplate-forme sur iOS, Android, web et PWA—couvre la fonctionnalité, l'interface utilisateur/expérience utilisateur, les performances, la sécurité, les appareils
Meilleur constructeur d'applications IA multiplateforme en 2026
Meilleur constructeur d'applications IA multiplateforme en 2026
Comparez les meilleurs constructeurs d'applications IA multiplateforme en 2026. Données indépendantes provenant de 345 sources publiques. Découvrez quelles plates-formes se déploient sur iOS, Android et le web à partir d'un seul projet.

Meilleures pratiques pour le déploiement d'applications multiplateforme
Déployez des applications sur le web, iOS et Android à partir d'une seule codebase : utilisez CI/CD, les tests multiplate-forme et les optimisations spécifiques à la plateforme pour gagner du temps

Guide ultime du déploiement d'applications multiplate-forme
Créer, publier et maintenir des applications iOS, Android et web à partir d'une seule codebase—comparer natif, hybride et PWA, optimiser les performances et suivre