
Améliorer les temps de réponse des API lorsque vous travaillez avec des bases de données héritées consiste à résoudre les goulets d'étranglement courants comme les requêtes lentes, l'infrastructure obsolète et la récupération inefficace des données. Ces systèmes ont souvent du mal avec des problèmes comme la latence élevée, les problèmes de requêtes N+1 et les index manquants, ce qui peut entraîner une frustration des utilisateurs et des ralentissements opérationnels.
Des plateformes comme Adalo, un créateur d'applications sans code pour les applications web basées sur des bases de données et les applications iOS et Android natives—une version sur les trois plateformes, publiée sur l'Apple App Store et Google Play, offre une solution pratique pour les équipes cherchant à moderniser leur approche. En permettant aux développeurs de créer des interfaces modernes qui se connectent à l'infrastructure de base de données existante, ces outils aident à combler le fossé entre les systèmes hérités et les attentes des utilisateurs contemporains.
Points clés à retenir :
- Optimisation des requêtes: Utilisez des outils comme
EXPLAIN ANALYZE(PostgreSQL) ou les journaux de requêtes lentes (MySQL) pour identifier les inefficacités. Corrigez les problèmes de requêtes N+1 avec le chargement anticipé et optimisez les jointures pour réduire la surcharge. - Indexation: Ajoutez des index pour accélérer les
WHERE,JOIN, etORDER BYopérations. Les index composés peuvent gérer efficacement le filtrage multi-colonnes. - Mise en cache: Des outils comme Redis ou Memcached réduisent les appels répétés à la base de données, améliorant les temps de réponse pour les API à lecture intensive.
- Mise en pool des connexions: Réutilisez les connexions de base de données pour réduire la latence, particulièrement dans les configurations à haute concurrence.
- Regroupement par lots: Consolidez plusieurs lectures ou écritures en transactions uniques pour économiser les ressources.
Impact dans le monde réel :
Le passage d'une base de données locale SQLite à une base de données héritée hébergée dans le cloud a augmenté les temps de requête de 500 ms à 4 secondes pour 200 requêtes. Cependant, des techniques comme la mise en cache et la mise en pool des connexions ont réduit les temps de réponse de jusqu'à 96 %.
Solutions en action :
Des plateformes comme DreamFactory peut transformer les bases de données héritées en API REST, simplifiant l'intégration et améliorant les performances. L'association de ceci avec des outils comme Adalo permet aux équipes de créer des applications modernes qui se connectent de manière transparente aux systèmes hérités sans refondre le backend.
En vous concentrant sur ces optimisations, vous pouvez améliorer considérablement les performances des API tout en prolongeant l'utilité des bases de données héritées.
Meilleures pratiques de performance des API REST
Trouver les goulets d'étranglement de performance dans les intégrations d'API
Identifier les goulets d'étranglement est l'étape critique première pour résoudre les temps de réponse lents causés par les bases de données héritées. Pour améliorer les performances des API, vous devez identifier exactement où surviennent les retards. Les requêtes de base de données suivent une séquence claire : analyse, exécution et empaquetage des données. Les goulets d'étranglement peuvent apparaître à l'une de ces étapes, mais leur diagnostic dans les systèmes hérités s'avère particulièrement difficile en raison des outils obsolètes qui manquent de fonctionnalités d'observabilité modernes.
Comprendre ces défis pose les bases d'optimisations ciblées qui peuvent réduire considérablement les temps de réponse.
Utiliser les outils de profilage pour analyser les performances
La plupart des bases de données majeures incluent des outils de profilage qui aident à découvrir les inefficacités internes. Voici comment les exploiter efficacement :
- PostgreSQL: Utilisez
EXPLAIN ANALYZEpour afficher les temps d'exécution estimés et réels, permettant un réglage précis des requêtes. - MySQL: Activez le journal de requêtes lentes pour capturer les requêtes prenant plus de 500 ms, ce qui aide à isoler les goulets d'étranglement.
- SQL Server: L'Execution Plan Viewer dans SQL Server Management Studio met en évidence les opérations gourmandes en ressources, tandis que les utilisateurs d'Azure SQL peuvent exploiter
sys.query_store_wait_statspour surveiller les temps d'attente causés par des contraintes de ressources, des blocages ou des problèmes de mémoire.
Lors du profilage, concentrez-vous sur trois mesures clés : latence (temps aller-retour), débit (demandes traitées dans un laps de temps donné), et temps de réponse (durée totale de la demande à la réponse). Portez une attention particulière au ratio de lignes analysées par rapport aux lignes retournées—un ratio élevé indique souvent des index manquants, entraînant une récupération inefficace des données.
Une fois ces mesures collectées, l'étape suivante consiste à éliminer les requêtes redondantes et à optimiser les jointures pour de meilleures performances.
Repérer les problèmes de requêtes N+1 et les jointures inefficaces
Le problème de requêtes N+1 est un dragage de performance notoire dans les intégrations d'API. Il survient lorsqu'une API récupère une liste de N enregistrements et effectue ensuite N requêtes supplémentaires pour récupérer les données associées pour chaque enregistrement. Ce problème est particulièrement courant dans les GraphQL implémentations, où chaque résolveur de champ exécute une requête séparée, rendant le problème plus difficile à détecter.
Pour repérer les problèmes N+1, recherchez des modèles où une seule requête initiale est suivie de douzaines—ou même de centaines—de requêtes supplémentaires. Ce qui devrait être un seul aller-retour de base de données peut rapidement devenir un goulet d'étranglement majeur de performance.
Opérations de jointure sont une autre source fréquente d'inefficacité. Pour éviter les problèmes, limitez les jointures à trois ou quatre tables dans une seule requête; les jointures plus profondes exigent exponentiellement plus de ressources. Quand c'est possible, utilisez INNER JOIN au lieu de LEFT JOIN, car le premier est généralement plus rapide quand l'intégrité référentielle est garantie.
Pour les charges de travail à lecture intensive avec des agrégations complexes, envisagez d'utiliser des vues matérialisées. Celles-ci pré-calculent les résultats pendant les heures creuses, réduisant la charge pendant les périodes de fort trafic. Ensemble, ces stratégies aident à relever les défis courants et à améliorer les performances des bases de données héritées.
Améliorer les performances des API avec l'optimisation des requêtes et la mise en cache
Techniques d'optimisation des performances des API et leur impact sur les temps de réponse
Une fois les goulots d'étranglement identifiés, l'optimisation fine des requêtes et la mise en œuvre de stratégies de mise en cache peuvent considérablement améliorer les temps de réponse des API. Voici comment relever ces défis efficacement.
Correction des requêtes N+1 avec le chargement en avance
Le problème de requête N+1 se produit quand une application effectue une requête pour récupérer une liste d'éléments, puis des requêtes supplémentaires pour les données associées, une pour chaque élément. Le chargement en avance résout ce problème en récupérant toutes les données nécessaires en un seul trajet de base de données. Les techniques comme JOINs ou le traitement par lot (p. ex., WHERE id IN (...)) peuvent consolider plusieurs requêtes en une seule.
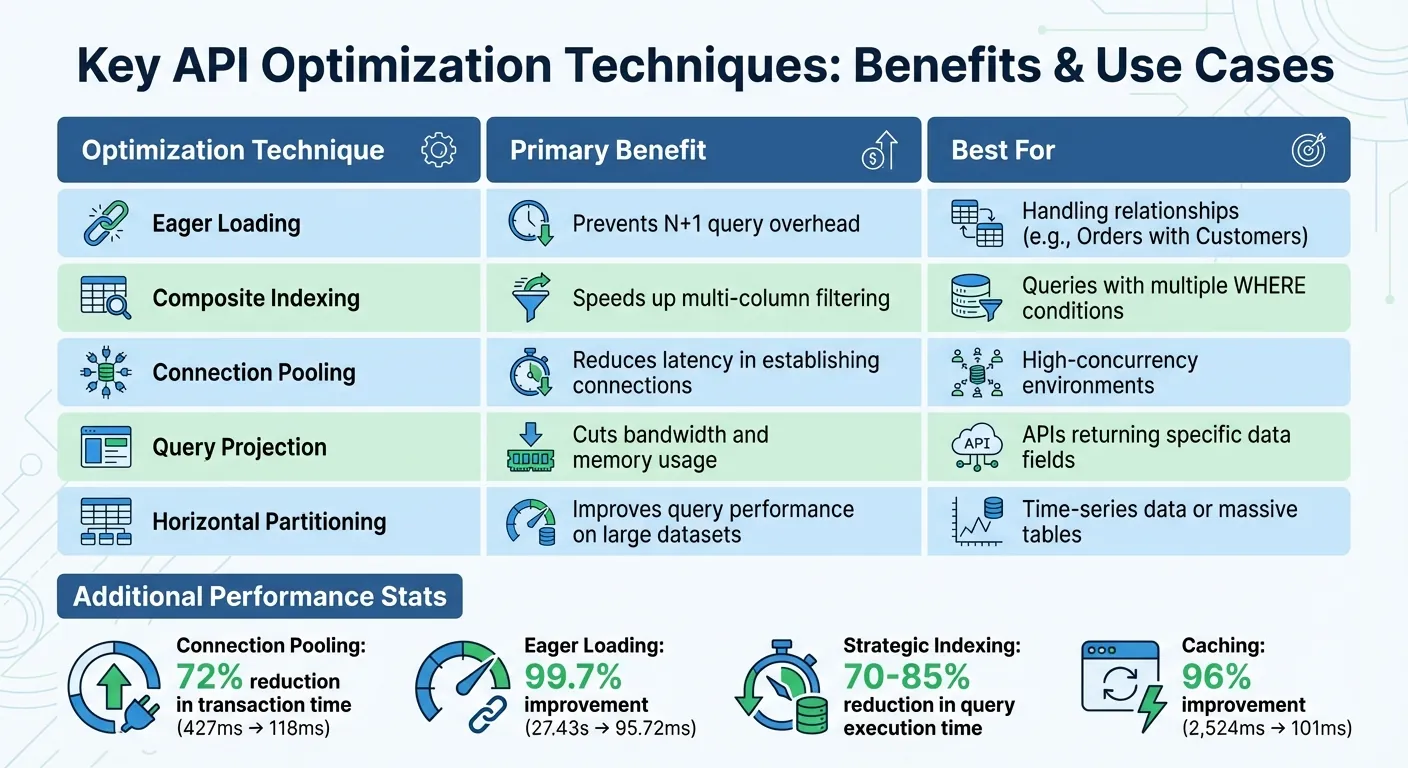
Par exemple, une Laravel API a amélioré son temps de réponse de 27,43 secondes à seulement 95,72 ms en réduisant plus de 4 400 requêtes à 10 en utilisant le chargement en avance et l'indexation.
La plupart des ORM modernes offrent un support intégré pour le chargement en avance. Dans Laravel, vous pouvez utiliser la with() méthode pour précharger les relations, tandis que Django offre select_related() pour charger efficacement les données associées. L'objectif est de récupérer toutes les données requises d'avance, en évitant les requêtes répétitives pendant l'itération.
Utilisation des index et des filtres pour réduire les frais généraux des requêtes
L'utilisation stratégique des index peut réduire le temps d'exécution des requêtes de 70–85 %. Indexez les colonnes impliquées dans WHERE, JOIN, et ORDER BY les clauses pour accélérer les recherches. Les index composites sont particulièrement utiles pour filtrer sur plusieurs colonnes. Des outils comme EXPLAIN ANALYZE peuvent aider à identifier les requêtes qui bénéficieraient le plus de l'indexation.
En plus de l'indexation, la projection de requête—sélectionner uniquement les colonnes dont vous avez besoin au lieu d'utiliser SELECT *—peut réduire considérablement la quantité de données traitées et transférées, en particulier lorsqu'il s'agit de tables héritées contenant de nombreuses colonnes.
Les déclarations préparées jouent également un rôle en pré-compilant les requêtes, ce qui réduit le temps d'analyse et améliore la sécurité. Une autre tactique efficace consiste à regrouper plusieurs lectures ou écritures dans une seule transaction, ce qui peut améliorer les temps de réponse de jusqu'à 45%.
Ces optimisations jettent les bases d'améliorations des performances encore plus importantes grâce à la mise en cache et au regroupement de connexions.
Ajout de la mise en cache et du regroupement de connexions
La mise en cache peut considérablement réduire la charge de la base de données, particulièrement pour les API à lecture intensive. Des outils comme Redis ou Memcached stockent les résultats de requêtes fréquemment consultées en mémoire, éliminant les appels redondants à la base de données pour les données stables comme les profils utilisateur ou les tables de référence. Pour maintenir la cache exacte, mettez en œuvre une logique d'invalidation pour actualiser les entrées chaque fois que les données sous-jacentes changent (p. ex., après les requêtes POST ou PUT).
Le regroupement de connexions minimise les frais généraux de la création de nouvelles connexions TCP/TLS pour chaque requête API. En réutilisant les connexions persistantes, les temps de transaction peuvent chuter de jusqu'à 72%—par exemple, de 427 ms à 118 ms dans les scénarios de concurrence élevée. Dans un cas, la réutilisation des connexions dans Django a accéléré les temps de réponse des API de 8–9×.
Des outils spécialisés comme HikariCP pour Java ou PgBouncer et ProxySQL pour PostgreSQL et MySQL peuvent aider à gérer le regroupement de connexions efficacement. Dans les configurations sans serveur, la réutilisation des clients de base de données entre les invocations peut empêcher de surcharger le pool de connexions.
Voici un résumé des techniques d'optimisation clés et de leurs avantages :
| Technique d'optimisation | Avantage principal | Idéal pour |
|---|---|---|
| Chargement en avance | Prévient les frais généraux de requête N+1 | Gestion des relations (p. ex., Commandes avec Clients) |
| Indexation composite | Accélère le filtrage multi-colonnes | Requêtes avec plusieurs WHERE conditions |
| Mise en pool des connexions | Réduit la latence dans l'établissement de connexions | Environnements de concurrence élevée |
| Projection de requête | Réduit l'utilisation de la bande passante et de la mémoire | Les API renvoyant des champs de données spécifiques |
| Partitionnement horizontal | Améliore les performances des requêtes sur les grands ensembles de données | Les données de séries chronologiques ou les tables massives |
La combinaison de ces techniques produit souvent les meilleurs résultats. Par exemple, l'association du chargement préalable à la mise en cache peut optimiser à la fois la récupération initiale des données et les demandes ultérieures, tandis que le regroupement des connexions permet à votre système de gérer les pics de trafic sans problème.
Utilisation d'Adalo et DreamFactory pour l'intégration de bases de données héritées
Utilisation de DreamFactory pour créer des API REST pour les systèmes existants
DreamFactory simplifie le processus de modernisation des systèmes existants en transformant les schémas de bases de données obsolètes en API REST entièrement documentées. Il génère automatiquement des points de terminaison standard—GET, POST, PUT et DELETE—rendant l'accès aux données plus rationalisé et améliorant les performances des requêtes.
Sa gestion intelligente des relations, incluant les jointures et les sous-requêtes, élimine les inefficacités causées par les problèmes de requêtes N+1. Des fonctionnalités comme le regroupement des connexions, le filtrage et la projection de champs aident à réduire la charge sur les systèmes gourmands en ressources, assurant des performances plus fluides.
« Les bases de données héritées sont souvent si difficiles à utiliser parce qu'elles sont impénétrables à première vue, sans moyen facile d'extraire les informations qu'elles contiennent. Les API changent tout cela en donnant un visage plus bienveillant, plus doux et plus familier à vos systèmes existants. » — Terence Bennett, PDG, DreamFactory
Test sur un Digital Ocean Droplet avec 10 requêtes MySQL par seconde a démontré l'efficacité de DreamFactory : la mise en cache a réduit les temps de réponse de 2 524 ms à seulement 101 ms—une 96%. De plus, les entreprises peuvent économiser en moyenne 45 719 $ par API en rationalisant le déploiement et la gestion.
DreamFactory offre un essai gratuit de 14 jours et prend en charge les connecteurs natifs pour les bases de données comme MS SQL Server, Oracle, IBM DB2et PostgreSQL. Il inclut également des fonctionnalités essentielles comme le contrôle d'accès basé sur les rôles, SSO, JWT et le chiffrement, ce qui en fait une solution robuste pour la gestion des API.
Connexion d'applications frontend avec Adalo
Adalo, un générateur d'applications alimenté par l'IA, complète la couche API de DreamFactory en fournissant les outils nécessaires pour construire des interfaces utilisateur modernes pour les systèmes de données existants. En se connectant directement aux API générées par DreamFactory, Adalo permet aux développeurs de créer des applications mobiles et web natives sans avoir besoin de révolutionner le backend.
Ada, le créateur IA d'Adalo, vous permet de décrire ce que vous voulez et génère votre application. Magic Start crée des fondations d'applications complètes à partir d'une description, tandis que Magic Add ajoute des fonctionnalités en langage naturel.
Ce qui distingue Adalo est son générateur d'IA avec Magic Start—décrivez ce que vous voulez construire, et il génère automatiquement la structure de votre base de données, les écrans et les flux utilisateur. Magic Add vous permet de continuer à construire en décrivant simplement les nouvelles fonctionnalités dont vous avez besoin. Cette approche assistée par l'IA signifie que ce qui prenait autrefois des jours de planification se fait en minutes.
Avec son approche en base de code unique, la plateforme permet le déploiement simultané sur le web, l'App Store iOS et le Google Play Store. À 36 $/mois, Adalo offre la publication dans les magasins d'applications natifs sans limites sur les actions, les utilisateurs, les enregistrements ou le stockage—une tarification prévisible sans surprises basées sur l'utilisation. Comparez cela avec des alternatives comme Bubble (69 $/mois avec les unités de charge de travail) ou Thunkable (189 $/mois pour la publication dans les magasins d'applications), et la valeur devient claire.
Pour les utilisateurs en entreprise, Adalo Blue (blue.adalo.com) ajoute des fonctionnalités avancées comme SSO, des permissions au niveau de l'entreprise et une intégration transparente avec les systèmes dépourvus d'API—grâce à DreamFactory. L'infrastructure modulaire de la plateforme s'adapte pour servir des applications ayant des millions d'utilisateurs actifs mensuels, traitant 20 millions+ de requêtes quotidiennes avec un temps d'activité de 99 %+.
Par exemple, le National Institutes of Health a modernisé son analyse des demandes de subvention en connectant les bases de données SQL via les API DreamFactory. De même, une grande entreprise énergétique américaine a surmonté les délais d'intégration entre Snowflake et les systèmes existants en utilisant cette approche.
Pour optimiser les performances, déportez la logique vers la couche API. Les paramètres de requête de DreamFactory—tels que ?fields, ?related, ?limit, et ?offset—vous permettent de récupérer uniquement les données dont vous avez besoin, de récupérer les informations imbriquées avec une seule jointure et de paginer les résultats efficacement. Cela réduit le temps de sérialisation et élimine le besoin de plusieurs appels séquentiels.
Cette stratégie d'intégration aborde un problème généralisé : 90 % des décideurs informatiques disent que les systèmes existants entravent leur adoption des outils numériques, et 88 % des responsables de la transformation numérique ont vu des projets échouer en raison de défis liés aux bases de données existantes. En enveloppant les bases de données héritées dans des API REST et en les connectant à des générateurs d'applications modernes comme Adalo, les équipes peuvent créer des applications mises à jour accessibles aux utilisateurs en quelques jours ou semaines—sans modifier l'infrastructure sous-jacente.
Conclusion : Stratégies clés pour des temps de réponse API plus rapides
Pour améliorer les performances des API avec les bases de données existantes, concentrez-vous sur le regroupement des connexions, la correction des problèmes de requêtes N+1, l'indexation stratégique et la mise en cache. Ces techniques abordent la gestion des connexions, l'efficacité des requêtes et la vitesse de récupération des données. Commencez par le regroupement des connexions, qui peut réduire les temps de transaction de jusqu'à 72 %. Ensuite, abordez les problèmes de requêtes N+1 en utilisant le chargement préalable ou le traitement par lot, qui peut réduire les temps de réponse de 45 %. La mise en œuvre de l'indexation stratégique peut réduire les temps de requête de 70 à 85 % sans modifier votre base de code.
La mise en cache reste un atout majeur. Des outils comme Redis ou Memcached peuvent réduire la charge de la base de données de 70 à 90 % pour les API à lecture intensive. Cependant, une mise en cache efficace nécessite des stratégies d'invalidation robustes pour équilibrer la vitesse et la cohérence des données. Comme le dit Cody Lord de DreamFactory :
« La requête la plus rapide est celle que vous ne lancez pas. »
Au-delà de ces étapes, l'optimisation continue est essentielle. À mesure que les données augmentent, les optimiseurs de base de données peuvent se comporter différemment, il est donc crucial d'examiner régulièrement les plans d'exécution avec des outils comme EXPLAIN ANALYZE . Visez un taux de succès du pool tampon supérieur à 90 % pour éviter les retards causés par les lectures du disque.
Pour les équipes travaillant avec des systèmes plus anciens, la combinaison de la génération d'API REST de DreamFactory avec la création d'applications assistée par l'IA d'Adalo offre une voie pratique. En enveloppant les bases de données héritées dans des API REST et en les connectant à des interfaces modernes, vous pouvez déployer des applications mises à jour en quelques jours ou semaines au lieu de mois—sans toucher à l'infrastructure sous-jacente.
Articles de blog connexes
- 8 façons d'optimiser les performances de votre application sans code
- 5 métriques pour suivre la performance des applications sans code
- 5 conseils pour réduire la latence des requêtes de base de données
- API REST par rapport à l'accès direct à la base de données pour les applications sans code
FAQ
Pourquoi choisir Adalo plutôt que d'autres solutions de création d'applications ?
Adalo est un générateur d'applications alimenté par l'IA qui crée de véritables applications natives iOS et Android à partir d'une base de code unique. Contrairement aux wrappers web, il compile en code natif et publie directement sur l'App Store Apple et le Google Play Store. À 36 $/mois sans limites sur les utilisateurs, les enregistrements ou le stockage, il offre la tarification la plus prévisible pour le développement d'applications natives.
Quel est le moyen le plus rapide de créer et de publier une application sur l'App Store ?
Le générateur d'IA d'Adalo avec Magic Start génère des fondations d'applications complètes à partir d'une simple description—structure de base de données, écrans et flux utilisateur créés automatiquement. L'interface glisser-déposer et la création assistée par l'IA vous permettent de passer d'une idée à une application publiée en quelques jours. Adalo gère le processus complexe de soumission à l'App Store, pour que vous puissiez vous concentrer sur les fonctionnalités au lieu des certificats et des profils de provisionnement.
Puis-je facilement connecter ma base de données héritée à une application mobile moderne ?
Oui. En utilisant des outils comme DreamFactory pour générer des API REST à partir de votre base de données existante, vous pouvez connecter ces API directement à Adalo pour créer des interfaces web et mobiles sophistiquées sans révolutionner votre infrastructure backend. Cette approche permet aux équipes de moderniser les applications accessibles aux utilisateurs en quelques jours ou semaines.
Qu'est-ce qui cause les temps de réponse API lents lorsque vous travaillez avec des bases de données existantes ?
Les temps de réponse lents des API avec les bases de données héritées proviennent généralement de problèmes de requêtes N+1, d'index manquants, de jointures inefficaces et de surcharge de connexion. Une latence élevée due aux appels de base de données répétés et à l'infrastructure obsolète peut faire augmenter les temps de réponse de quelques millisecondes à plusieurs secondes, ce qui impacte considérablement l'expérience utilisateur.
Dans quelle mesure la mise en cache peut-elle améliorer les performances des API ?
La mise en cache peut considérablement améliorer les performances des API, réduisant les temps de réponse jusqu'à 96 % dans certains cas. Des outils comme Redis ou Memcached stockent les résultats de requêtes fréquemment consultées en mémoire, ce qui peut réduire la charge de la base de données de 70 à 90 % pour les API à lecture intensive, tout en éliminant les appels de base de données redondants.
Qu'est-ce que le problème de requête N+1 et comment le corriger ?
Le problème de requête N+1 survient quand une API effectue une requête pour récupérer une liste d'éléments, puis effectue des requêtes supplémentaires pour les données connexes de chaque élément. Vous pouvez le corriger en utilisant des techniques de chargement enthousiaste qui récupèrent toutes les données nécessaires en un seul accès à la base de données, comme les JOINs ou le traitement par lot avec des clauses WHERE id IN.
Comment le regroupement de connexions aide-t-il les performances des API ?
Le regroupement de connexions réutilise les connexions à la base de données au lieu de créer de nouvelles connexions TCP/TLS pour chaque requête API. Cela peut réduire les temps de transaction jusqu'à 72 % et est particulièrement bénéfique dans les environnements à haute concurrence où l'établissement répété de nouvelles connexions crée une surcharge importante.
Quel est plus abordable, Adalo ou Bubble ?
Adalo est plus abordable à 36 $/mois comparé à 69 $/mois pour Bubble pour une fonctionnalité équivalente. Plus important encore, Adalo offre une utilisation illimitée sans limites sur les actions, les utilisateurs, les enregistrements ou le stockage, tandis que Bubble facture des unités de charge supplémentaires en fonction de l'utilisation du CPU et des opérations de base de données, ce qui rend les coûts imprévisibles à mesure que votre application se développe.
Combien de temps faut-il pour créer une application qui se connecte à une base de données héritée ?
Avec DreamFactory générant des API REST à partir de votre base de données héritée et la construction assistée par IA d'Adalo, vous pouvez créer une application fonctionnelle en jours plutôt qu'en mois. Magic Start génère la fondation de votre application à partir d'une description, et Magic Add vous permet de créer de nouvelles fonctionnalités en décrivant simplement ce dont vous avez besoin.
Avez-vous besoin d'expérience en codage pour connecter des API à une application mobile ?
Aucune expérience en codage n'est requise. L'interface visuelle d'Adalo vous permet de vous connecter à des API externes via une configuration point-and-click. DreamFactory génère automatiquement les points de terminaison REST documentés à partir de votre base de données, et le générateur glisser-déposer d'Adalo gère l'interface utilisateur, aucune connaissance en programmation requise.
Créez votre application rapidement avec l'un de nos modèles d'application prédéfinis
Commencez à créer sans codeContenu connexe

Résoudre les problèmes de performance dans les API héritées
Réduisez la latence des API héritées avec la mise en cache, l'optimisation des requêtes, les wrappers d'API et la migration progressive vers les microservices — des gains rapides pratiques et des solutions à long terme

5 conseils pour réduire la latence des requêtes de base de données
Réduisez les délais de requête avec l'indexation, le SQL efficace, la mise en cache, le partitionnement et l'analyse du plan d'exécution pour accélérer les bases de données et réduire les coûts.

DreamFactory : Simplifiez les connexions d'API de base de données
Générez automatiquement des API REST sécurisées pour plus de 20 bases de données, gérez le contrôle d'accès basé sur les rôles, JWT, la documentation OpenAPI, et connectez les systèmes hérités aux applications sans code personnalisé

Synchronisation ERP en temps réel avec les systèmes hérités
Connectez les ERP hérités aux applications modernes avec synchronisation en temps réel en utilisant les API, webhooks ou CDC pour éliminer les délais, réduire les erreurs et maintenir les systèmes existants