
Les requêtes de base de données lentes drainent silencieusement les performances de votre application, frustrant les utilisateurs et gonflant les coûts d'infrastructure. Ces cinq techniques éprouvées vous aideront à éliminer les goulots d'étranglement de latence et à offrir l'expérience rapide et réactive que vos utilisateurs attendent.
Une approche qui simplifie l'optimisation de la base de données est la création avec Adalo—un créateur d'applications sans code pour les applications web basées sur une base de données et les applications iOS et Android natives—une version sur les trois plateformes, publiée sur l'Apple App Store et Google Play. La base de données intégrée d'Adalo offre une latence API nulle, tandis que son infrastructure gère la mise en cache et l'optimisation des requêtes automatiquement, afin que vous puissiez vous concentrer sur votre application au lieu d'un réglage manuel de la base de données.
Que vous optimisiez un système existant ou que vous lanciez un nouveau MVP, faire entrer votre application dans les app stores rapidement signifie atteindre le plus grand public possible avec les notifications push et les performances natives. Voici comment rendre vos requêtes de base de données ultra-rapides.
La latence des requêtes de base de données peut ralentir les performances de votre application, frustrante les utilisateurs et augmentant les coûts. Que vous construisiez un simple outil interne ou une application orientée client avec des milliers d'utilisateurs, les requêtes lentes créent des goulots d'étranglement qui se répercutent dans tout votre système. Voici comment corriger cela :
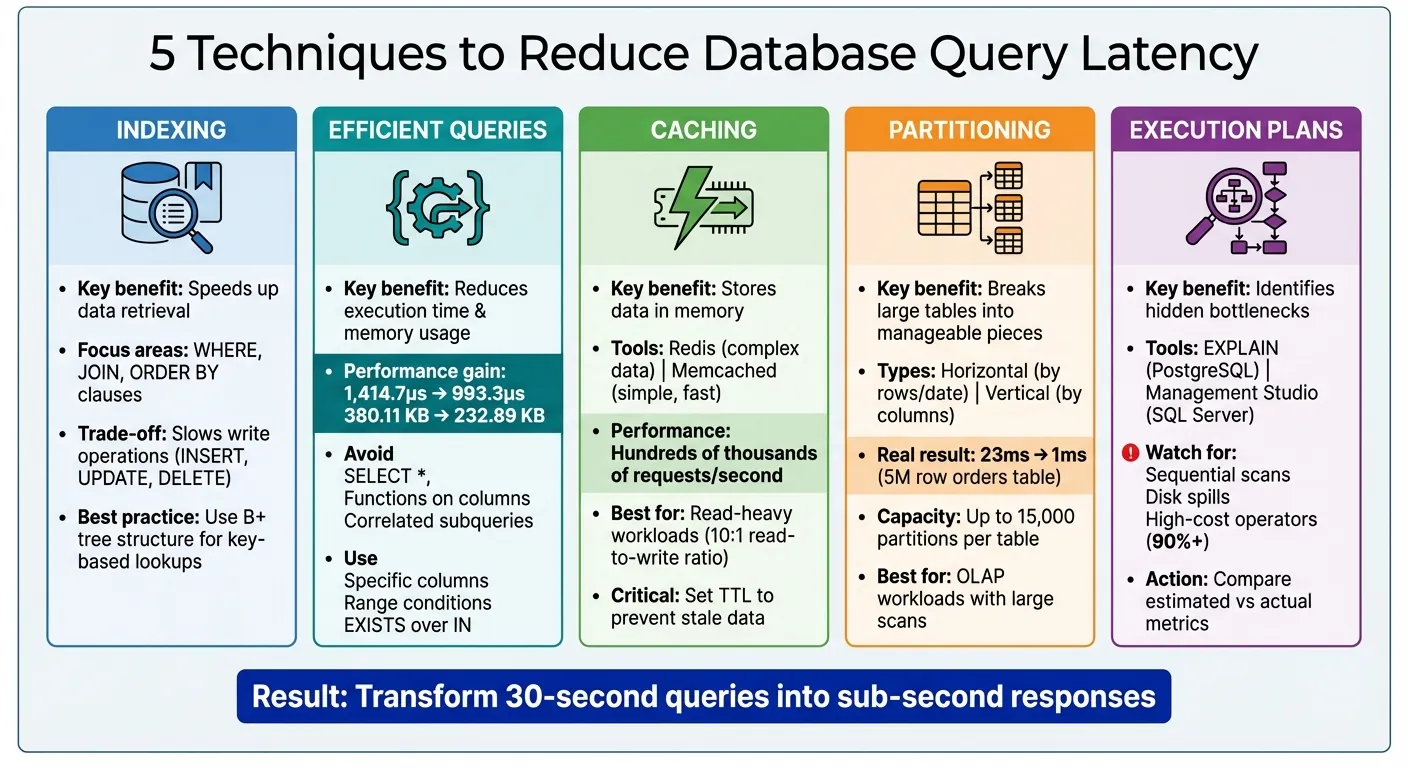
- Indexation: Utilisez des index pour accélérer la récupération de données en ciblant les colonnes dans
WHERE,JOIN, etORDER BYclauses. Évitez la surindexation pour prévenir les opérations d'écriture plus lentes. - Requêtes efficaces: Évitez
SELECT *, optimisezWHEREconditions pour l'utilisation d'index, et minimisez les jointures ou sous-requêtes inutiles. - Mise en cache: Stockez les données fréquemment consultées en mémoire à l'aide d'outils comme Redis ou Memcached pour réduire la charge de la base de données. Utilisez
TTLpour maintenir les données en cache à jour. - Partitionnement: Divisez les grandes tables en parties plus petites ou synchronisez les données entre les plateformes (horizontalement ou verticalement) pour améliorer les performances des requêtes sur des ensembles de données massifs.
- Plans d'exécution des requêtes: Analysez les plans d'exécution pour identifier les goulots d'étranglement comme les analyses séquentielles ou les débordements de disque. Ajustez les index et les structures de requête en conséquence.
Optimisation de la latence des requêtes de base de données : 5 techniques clés comparées
Pourquoi mes requêtes de base de données s'exécutent-elles si lentement ? - Next LVL Programming
1. Utiliser l'indexation de la base de données
Considérez les index de base de données comme l'index à la fin d'un livre—ils agissent comme des raccourcis, pointant directement vers les lignes dont vous avez besoin dans une table. Cela évite au moteur de base de données de scanner chaque ligne, rendant la récupération de données beaucoup plus rapide. La plupart des index reposent sur une structure d'arbre B+, qui est conçue pour les recherches rapides basées sur des clés. La mise en place d'une indexation appropriée est une étape clé vers l'optimisation de vos requêtes de base de données, en particulier lors de l'évaluation options d'intégration de base de données pour votre application.
Concentrez-vous sur l'indexation des colonnes couramment utilisées dans WHERE, JOIN, et ORDER BY clauses—cela peut entraîner des améliorations notables dans les performances des requêtes. Par exemple, un index couvrant peut récupérer toutes les colonnes nécessaires directement, réduisant les opérations d'entrée/sortie inutiles.
Pour les requêtes plus simples, les index à colonne unique font souvent l'affaire. Cependant, pour les requêtes avec plusieurs conditions, les index composites sont le chemin à suivre. Lors de la création d'index composites, organisez les colonnes stratégiquement : commencez par les filtres d'égalité, suivez avec les filtres de plage, puis considérez la distinctivité des colonnes.
Bien que les index accélèrent les SELECT opérations, ils comportent un compromis—ils peuvent ralentir les opérations d'écriture comme INSERT, UPDATE, et DELETE. Pour éviter les frais généraux inutiles, gardez un œil sur la façon dont vos index sont utilisés et supprimez ceux qui n'ajoutent pas de valeur.
« Une erreur de conception courante est de créer de nombreux index de manière spéculative pour 'donner des choix à l'optimiseur'. La surindexation qui en résulte ralentit les modifications de données et peut causer des problèmes de concurrence. » - Guide de conception d'index Microsoft SQL Server
Meilleures pratiques d'indexation
Lors de la mise en œuvre d'index, considérez ces directives :
- Les clés primaires sont automatiquement indexées dans la plupart des systèmes de base de données
- Les clés étrangères utilisées dans les jointures bénéficient considérablement de l'indexation
- Les colonnes avec une cardinalité élevée (de nombreuses valeurs uniques) sont de meilleurs candidats à l'index que les colonnes avec peu de valeurs distinctes
- Auditez régulièrement vos index pour identifier ceux qui ne sont pas utilisés et qui n'ajoutent que de la surcharge d'écriture
Adalo est un créateur d'applications sans code pour les applications web basées sur une base de données et les applications iOS et Android natives—une version sur les trois plateformes, publiées sur l'Apple App Store et Google Play. Les créateurs d'applications modernes alimentés par l'IA comme Adalo gèrent automatiquement une grande partie de cette complexité. Avec la refonte de l'infrastructure 2026 de la plateforme, les opérations de base de données s'exécutent 3 à 4 fois plus vite qu'avant, et le système adapte l'infrastructure selon les besoins de l'application—ce qui signifie qu'il n'y a pas de limite d'enregistrements sur les plans payants. Cela élimine le besoin d'optimiser manuellement les index pour la plupart des cas d'usage courants.
2. Écrire des requêtes plus efficaces
La façon dont vous structurez une requête peut faire toute la différence en matière de performance. Pour commencer, évitez d'utiliser SELECT *. Spécifiez plutôt uniquement les colonnes dont vous avez réellement besoin. Par exemple, si vous travaillez avec un base de données clients et que vous n'avez besoin que de l'ID, du nom et de l'email, demandez simplement ces trois champs. L'extraction de colonnes inutiles gaspille de la mémoire et de la bande passante.
La structure de la requête est tout aussi importante que l'indexation. L'utilisation de la récupération complète d'entités dans les ORM (Object-Relational Mappers) peut ajouter un surcoût important. Un benchmark a révélé que le passage à des requêtes sans suivi a réduit le temps d'exécution de 1 414,7 microsecondes à 993,3 microsecondes et a diminué l'utilisation de la mémoire de 380,11 KB à 232,89 KB. Pour éviter ce surcoût, utilisez des projections dans votre ORM—des méthodes comme .Select() dans EF Core ou .values() dans Django—pour récupérer uniquement les champs dont vous avez besoin.
Optimisation des conditions WHERE
Lors de l'optimisation des conditions WHERE, soyez attentif à la façon dont vous les écrivez. Les fonctions sur les colonnes, comme WHERE YEAR(hire_date) = 2020, empêchent les index d'être utilisés efficacement. À la place, utilisez des conditions basées sur les plages, telles que WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01'. Cette approche maintient la « SARG-ability » (Search ARGument-ability), permettant à la requête de tirer parti des index. De la même façon, évitez les modèles avec des caractères génériques en début dans les requêtes LIKE , car ils forcent des analyses complètes de table.
« Le facteur décisif principal pour savoir si une requête s'exécute rapidement ou non est de savoir si elle utilisera correctement les index le cas échéant. »
– Documentation Microsoft
Réduire les jointures et les sous-requêtes
Réduisez l'utilisation des jointures et des sous-requêtes inutiles. Les sous-requêtes corrélées—celles qui dépendent de la requête externe—sont particulièrement problématiques, car elles s'exécutent une fois pour chaque ligne du résultat. À la place, remplacez-les par des jointures standard autant que possible. Si vous vérifiez l'existence de données, utilisez EXISTS au lieu de IN. EXISTS clause s'arrête dès qu'elle trouve une correspondance, ce qui la rend beaucoup plus efficace.
Comme l'explique Mike Payne, un expert en bases de données : « L'optimisation de ces requêtes est la chose la plus impactante que vous puissiez faire pour améliorer la vitesse et l'évolutivité de votre base de données ».
Ada, le créateur IA d'Adalo, vous permet de décrire ce que vous voulez et génère votre application. Magic Start crée des fondations d'applications complètes à partir d'une description, tandis que Magic Add ajoute des fonctionnalités en langage naturel.
Pour ceux qui construisent des applications sans écrire SQL directement, l'interface visuelle d'Adalo abstrait ces optimisations. Les fonctionnalités assistées par l'IA de la plateforme, comme Ajout magique vous permettent de décrire les données dont vous avez besoin en langage naturel, et le système génère automatiquement des requêtes efficaces. Cela est particulièrement utile pour les créateurs non techniques qui veulent une bonne performance sans approfondir l'optimisation des requêtes.
3. Mettre en cache les requêtes fréquemment utilisées
La mise en cache est comme donner un coup de pouce à la mémoire de votre application. Au lieu d'interroger constamment la base de données, les données fréquemment accessibles sont stockées dans la mémoire, ce qui réduit le temps nécessaire pour récupérer les informations. Cela évite les délais liés à l'accès au disque, qui—même dans le meilleur des cas—peut prendre des dizaines de millisecondes.
Deux outils populaires pour la mise en cache sont Redis et Memcached. Redis se distingue par sa capacité à gérer des structures de données complexes et son option de persistance sur disque. En revanche, Memcached est plus simple et plus léger, conçu uniquement pour la mise en cache à très grande vitesse. Pour vous donner une idée de leur puissance, un seul nœud de cache en mémoire peut traiter des centaines de milliers de requêtes par seconde.
Modèle Cache-Aside
La méthode de mise en cache la plus courante est cache-aside, aussi appelée chargement lent. Voici comment cela fonctionne : l'application vérifie d'abord le cache. Si les données n'y sont pas (un « miss »), elle interroge la base de données, récupère les données, puis met à jour le cache. Cette méthode est particulièrement efficace dans les scénarios à forte lecture où les données sont lues au moins 10 fois plus souvent qu'elles ne sont écrites. En combinant cette stratégie avec les techniques d'optimisation de requête antérieures, vous pouvez réduire considérablement la charge sur votre base de données.
Pour éviter que les données obsolètes ne traînent, définissez toujours une TTL (durée de vie) pour vos données en cache. Si vous travaillez avec Redis, envisagez d'utiliser Hashes pour stocker les lignes de la base de données. Cette approche vous permet de mettre à jour des champs individuels sans avoir besoin de traiter un blob JSON entier. De plus, surveillez votre taux de succès du cache—un faible taux signifie que votre cache n'est pas utilisé efficacement, ce qui gaspille de la mémoire sans soulager la charge de la base de données.
« La vitesse et le débit de votre base de données peuvent être le facteur le plus impactant pour les performances globales de l'application. » – AWS
Quand implémenter la mise en cache
Pas toutes les applications ont besoin d'une couche de mise en cache dédiée. Envisagez de mettre en place la mise en cache quand :
- Vos requêtes de base de données sont constamment lentes malgré l'optimisation
- Les mêmes données sont demandées à plusieurs reprises par plusieurs utilisateurs
- Votre application subit des pics de trafic qui submergent la base de données
- Les opérations de lecture sont nettement plus nombreuses que les opérations d'écriture
L'infrastructure modulaire d'Adalo gère la mise en cache au niveau de la plateforme, ce qui signifie que les applications construites sur la plateforme bénéficient d'une récupération de données optimisée sans configuration de cache manuelle. Le système traite 20 millions+ de requêtes de données quotidiennement avec un uptime de 99 %+, démontrant l'efficacité de ses optimisations de performance intégrées.
4. Partitionner les grands ensembles de données
Lorsque les tables atteignent des millions de lignes, même les requêtes les mieux indexées peuvent commencer à ralentir. Partitionnement offre un moyen de relever ce défi en divisant les grandes tables en petits morceaux plus gérables—appelés partitions—tout en les traitant comme une seule table logique. Cela permet au moteur de base de données d'utiliser l'élimination de partitions, qui ignore les partitions non pertinentes lors d'une requête, réduisant considérablement la quantité de données à analyser. La clé est de choisir la bonne méthode pour diviser vos données afin d'assurer un scan efficace.
Partitionnement horizontal vs. vertical
Il existe deux façons principales de partitionner les données : partitionnement horizontal et partitionnement vertical.
- Partitionnement horizontal divise la table par lignes, souvent en fonction d'une colonne spécifique comme une date ou une région. Par exemple, vous pouvez diviser une table de ventes en blocs mensuels. Cette méthode fonctionne particulièrement bien pour les données de séries chronologiques ou les scénarios où les requêtes filtrent fréquemment par une plage spécifique.
- Partitionnement vertical, en revanche, sépare les colonnes. C'est idéal pour les tables larges avec de nombreux champs, surtout si seules quelques colonnes sont régulièrement consultées. Par exemple, vous pouvez déplacer les grands BLOBs ou les champs rarement utilisés dans des tables distinctes.
Voici un exemple concret : le partitionnement d'une table Airtable de commandes de 5 000 000 lignes par mois a réduit le temps de requête de 23 ms à seulement 1 ms. Les moteurs de base de données modernes comme SQL Server peuvent gérer jusqu'à 15 000 partitions par table. Cependant, il est important de ne pas en faire trop—le surpartitionnement peut entraîner une utilisation accrue de la mémoire et nuire aux performances si les requêtes finissent par analyser plusieurs partitions.
| Type de partitionnement | Méthode | Idéal pour |
|---|---|---|
| Horizontal | Divise les lignes (p. ex., par plage de date ou d'ID) | Grands ensembles de données avec requêtes basées sur des plages |
| Vertical | Divise les colonnes (p. ex., en séparant les BLOBs des champs fréquemment consultés) | Tables larges où seules quelques colonnes sont régulièrement interrogées |
Choisir la bonne clé de partitionnement
Pour que le partitionnement fonctionne efficacement, choisissez une colonne fréquemment utilisée dans les clauses WHERE. Cela garantit que la base de données peut pleinement tirer parti de l'élimination de partitions. De plus, alignez vos index avec le schéma de partitionnement pour améliorer les tâches de maintenance. Le partitionnement convient particulièrement bien aux charges de travail OLAP impliquant des analyses de grande envergure, plutôt qu'aux systèmes OLTP où les requêtes extraient généralement des lignes individuelles.
Pour les créateurs d'applications travaillant avec de grands ensembles de données, l'infrastructure d'Adalo s'adapte maintenant aux besoins de l'application—il n'y a pas de limite supérieure au nombre d'enregistrements de base de données pour les forfaits payants. Avec les bonnes configurations de relations de données, les applications créées sur la plateforme peuvent évoluer au-delà de 1 million d'utilisateurs actifs mensuels. Cela élimine le besoin de stratégies de partitionnement manuel que d'autres plateformes avec des limites d'enregistrements exigent.
5. Examiner les plans d'exécution des requêtes
Une fois que vous avez abordé l'indexation et la refonte des requêtes, plonger dans les plans d'exécution peut fournir des informations plus approfondies sur les performances des requêtes. Même les requêtes bien optimisées peuvent rencontrer des goulots d'étranglement inattendus, et les plans d'exécution aident à découvrir comment la base de données traite une requête. Ils détaillent des éléments tels que l'utilisation des index, les méthodes de jointure et les opérations de tri.
Utiliser EXPLAIN et les outils de plan d'exécution
Dans PostgreSQL, des outils comme EXPLAIN et EXPLAIN ANALYZE sont inestimables. EXPLAIN fournit des coûts estimés, tandis que EXPLAIN ANALYZE ajoute des métriques de performance réelles, telles que les décomptes de lignes et les temps d'exécution. En comparant ces éléments, vous pouvez identifier les écarts qui pourraient indiquer des statistiques obsolètes ou une indexation sous-optimale. De même, les plans d'exécution réels de SQL Server dans Management Studio offrent des informations comparables. Ces outils aident à identifier les inefficacités qui pourraient ne pas être évidentes par d'autres techniques d'optimisation.
Points à surveiller
Lors de l'analyse d'un plan d'exécution, faites attention aux modèles tels que « Sequential Scan » sur les grandes tables. Cela suggère souvent que l'ajout d'un index pourrait améliorer les performances. Recherchez également les conditions de filtre qui éliminent la plupart des lignes après l'analyse, car celles-ci pourraient bénéficier de la conversion en opération « Index Cond ». Un autre signal d'alarme est les opérations de tri ou de hachage débordant sur le disque, ce qui peut augmenter considérablement la latence des requêtes. La comparaison du temps CPU au temps écoulé peut également révéler si votre requête est limitée par l'utilisation du CPU ou si elle attend des opérations d'E/S.
Si un opérateur unique, comme « Sort » ou « Hash Join », représente 90 % du coût de la requête, c'est une cible claire pour l'optimisation. Vous pouvez également expérimenter la désactivation temporaire de certaines options du planificateur pour tester des stratégies de jointure alternatives et voir si elles fonctionnent mieux en pratique. Soyez attentif aux avertissements concernant les conversions de types de données implicites, car celles-ci peuvent forcer le moteur à traiter chaque ligne individuellement, minant l'efficacité de l'index.
Analyse des performances automatisée
Pour ceux qui préfèrent ne pas analyser manuellement les plans d'exécution, Adalo offre X-Ray—une fonction d'IA qui identifie les problèmes de performance avant qu'ils n'affectent les utilisateurs. Cette approche proactive de la surveillance des performances signifie que vous pouvez détecter et corriger les goulots d'étranglement sans plonger dans les mécanismes internes de la base de données. La fonction met en évidence les préoccupations potentielles en matière de scalabilité et suggère des optimisations, ce qui est particulièrement précieux pour les créateurs non techniques qui développent leurs applications.
Comparaison des approches de base de données pour les créateurs d'applications
Lors du choix d'une plateforme de création d'applications, les performances et la scalabilité de la base de données doivent être les principales considérations. Différentes plateformes gèrent le stockage des données et l'optimisation des requêtes de façons fondamentalement différentes.
| Plateforme | Approche de base de données | Limites d'enregistrement | Prix de départ |
|---|---|---|---|
| Adalo | Intégrée + connexions externes | Illimité sur les forfaits payants | 36 $/mois |
| Bubble | Intégrée avec unités de charge de travail | Limité par les calculs de charge de travail | 69 $/mois |
| Glide | Basé sur feuille de calcul | Limité, des frais supplémentaires s'appliquent | 60 $/mois |
| FlutterFlow | Externe uniquement (géré par l'utilisateur) | Dépend du fournisseur externe | 70 $/mois + coûts de base de données |
Bubble offre plus d'options de personnalisation, mais cette flexibilité entraîne souvent des applications plus lentes qui souffrent sous une charge accrue. De nombreux utilisateurs de Bubble finissent par embaucher des experts pour optimiser leurs applications — les affirmations de millions d'utilisateurs actifs mensuels ne sont généralement réalisables qu'avec une aide professionnelle. La solution d'application mobile de Bubble est également un wrapper pour l'application web, ce qui introduit des défis potentiels à grande échelle.
FlutterFlow est techniquement « low-code » plutôt que « no-code » et cible les utilisateurs techniques. Les utilisateurs doivent configurer et gérer leur propre base de données externe, ce qui nécessite une complexité d'apprentissage importante. Toute configuration moins qu'optimale peut créer des problèmes d'échelle, c'est pourquoi l'écosystème FlutterFlow regorge d'experts rémunérés.
Glide excelle avec les applications basées sur des feuilles de calcul, mais crée des applications génériques et simplistes avec une liberté créative limitée. Il ne supporte pas la publication sur l'Apple App Store ou le Google Play Store, ce qui limite les options de distribution.
Conclusion
Réduire la latence des requêtes de base de données consiste à améliorer la vitesse et à assurer la scalabilité. Des techniques comme l'indexation, l'écriture de requêtes efficaces, la mise en cache, le partitionnement et l'examen des plans d'exécution peuvent transformer des requêtes lentes de 30 secondes en réponses ultra-rapides et inférieures à une seconde.
Mais les avantages vont au-delà de la vitesse. Les requêtes simplifiées consomment moins de ressources serveur, ce qui peut réduire les coûts mensuels et garantir une expérience plus fluide au fur et à mesure que votre base d'utilisateurs se développe. Les requêtes efficaces aident également à réduire la charge du serveur et à éviter de dépasser les limites de taux d'API, comme Airtablela restriction de 5 requêtes par seconde. De petits ajustements maintenant peuvent vous épargner de gros problèmes à l'avenir.
Adalo, un créateur d'applications alimenté par l'IA, simplifie ces optimisations grâce à son interface visuelle et son backend intégré. Pour les applications avec des ensembles de données plus petits, la base de données intégrée d'Adalo fournit une latence d'API nulle avec des performances rapides. Vous avez besoin de mettre à l'échelle ou de travailler en collaboration ? Vous pouvez vous connecter à des bases de données externes comme Airtable, PostgreSQL ou MS SQL Server en utilisant les Collections externes, disponibles sur le plan Professionnel à partir de 36 $ par mois. Cette flexibilité vous permet de commencer avec une configuration simple et de mettre à l'échelle selon vos besoins sans refondre votre application.
Pour commencer, concentrez-vous sur le profilage de vos requêtes les plus lentes avec des outils comme EXPLAIN et abordez d'abord les goulots d'étranglement les plus pressants. Qu'il s'agisse d'ajouter un index ou de configurer une couche de mise en cache, chaque amélioration s'appuie sur la précédente. Comme le note judicieusement Mike Payne de Paessler :
« Vous ne pouvez pas optimiser ce que vous ne voyez pas. La surveillance des bases de données fait la lumière sur exactement où résident les problèmes de performance. »
Une fois que vous avez identifié les points problématiques, les solutions sont souvent simples et offrent des résultats immédiats.
Articles de blog connexes
- 8 façons d'optimiser les performances de votre application sans code
- Comment créer une application à l'aide des données IBM DB2
- 5 métriques pour suivre la performance des applications sans code
- Mise à l'échelle d'applications sans code pour de grands ensembles de données
FAQ
Pourquoi choisir Adalo plutôt que d'autres solutions de création d'applications ?
Adalo est un créateur d'applications alimenté par l'IA qui crée de véritables applications natives iOS et Android. Contrairement aux wrappers web, il se compile en code natif et se publie directement à la fois sur l'Apple App Store et Google Play Store à partir d'une seule base de code, ce qui facilite la partie la plus difficile du lancement d'une application.
Quel est le moyen le plus rapide de créer et de publier une application sur l'App Store ?
L'interface glisser-déposer d'Adalo combinée à la création assistée par l'IA via Magic Start et Magic Add vous permet de créer des applications complètes en heures plutôt qu'en semaines. La plateforme gère l'ensemble du processus de soumission à l'App Store, supprimant les barrières techniques qui ralentissent généralement les lancements d'applications.
Puis-je facilement optimiser les requêtes de base de données dans mon application ?
Oui, grâce à l'interface visuelle d'Adalo et à son backend intégré, vous pouvez optimiser les performances de la base de données sans écrire de SQL. Pour les applications avec des ensembles de données plus petits, la base de données intégrée d'Adalo fournit une latence d'API nulle, et vous pouvez vous connecter à des bases de données externes comme PostgreSQL ou Airtable pour les ensembles de données plus volumineux en utilisant les Collections externes.
Quel est le moyen le plus impactant de réduire la latence des requêtes de base de données ?
L'indexation appropriée des bases de données est souvent la première étape la plus impactante, car les index agissent comme des raccourcis qui pointent directement vers les lignes nécessaires au lieu de scanner des tables entières. Concentrez-vous sur l'indexation des colonnes couramment utilisées dans les clauses WHERE, JOIN et ORDER BY pour les meilleurs gains de performance.
Quand dois-je utiliser la mise en cache par rapport au partitionnement pour les grands ensembles de données ?
Utilisez la mise en cache lorsque vous avez des données fréquemment accessibles qui ne changent pas souvent — des outils comme Redis ou Memcached peuvent traiter des centaines de milliers de requêtes par seconde. Utilisez le partitionnement lorsque vos tables se développent en millions de lignes et que les requêtes filtrent par des plages spécifiques comme les dates, car cela permet à la base de données de sauter entièrement les données non pertinentes.
Comment identifier les requêtes qui causent des problèmes de performance ?
Utilisez des outils de plan d'exécution de requête comme EXPLAIN dans PostgreSQL ou les plans d'exécution réels dans SQL Server pour voir exactement comment la base de données traite vos requêtes. Adalo propose également X-Ray, une fonctionnalité d'IA qui identifie les problèmes de performance avant qu'ils ne touchent les utilisateurs.
Pourquoi dois-je éviter d'utiliser SELECT * dans mes requêtes de base de données ?
Utiliser SELECT * récupère toutes les colonnes d'une table, gaspillant la mémoire et la bande passante lorsque vous n'avez besoin que de champs spécifiques. Spécifier uniquement les colonnes dont vous avez besoin peut réduire considérablement le temps d'exécution et l'utilisation de la mémoire — les benchmarks montrent que le passage à des requêtes ciblées peut réduire la consommation de mémoire de près de 40 %.
Quel est plus abordable, Adalo ou Bubble ?
Adalo commence à 36 $/mois avec une utilisation illimitée et sans plafond de dossiers sur les forfaits payants. Bubble commence à 69 $/mois avec des frais d'unités de charge basés sur l'utilisation et des limites de dossiers. Adalo inclut également des mises à jour d'applications illimitées une fois publiées, tandis que Bubble a des restrictions de republication.
Adalo est-il meilleur que FlutterFlow pour les applications mobiles ?
Pour les utilisateurs non techniques, oui. FlutterFlow est « low-code » ciblant les utilisateurs techniques qui doivent configurer et gérer leur propre base de données externe. Adalo inclut une base de données intégrée sans limites d'enregistrements sur les forfaits payants, et son créateur visuel est décrit comme « facile comme PowerPoint » tout en produisant toujours des applications iOS et Android natives.
Adalo a-t-elle des limites de enregistrements de base de données ?
Non. Les forfaits payants ont des enregistrements de base de données illimités sans plafonds. Avec les bonnes configurations de relations de données, les applications Adalo peuvent évoluer au-delà de 1 million d'utilisateurs actifs mensuels. L'infrastructure modulaire de la plateforme se met à l'échelle automatiquement selon les besoins de votre application.
Créez votre application rapidement avec l'un de nos modèles d'application prédéfinis
Commencez à créer sans codeContenu connexe

Améliorer le temps de réponse des API avec les bases de données héritées
Accélérez les API utilisant les bases de données héritées avec l'optimisation des requêtes, l'indexation, la mise en cache, le regroupement de connexions et les corrections des requêtes N+1 pour réduire la latence

Résoudre les problèmes de performance dans les API héritées
Réduisez la latence des API héritées avec la mise en cache, l'optimisation des requêtes, les wrappers d'API et la migration progressive vers les microservices — des gains rapides pratiques et des solutions à long terme

Comment l'IA et les microapplications vont transformer le flux de travail d'entreprise
Les microapplications alimentées par l'IA automatisent les tâches répétitives, modernisent les systèmes hérités et permettent les constructions d'applications sans code pour accélérer les flux de travail, réduire les coûts et

L'avenir du SaaS : automatisation des flux de travail alimentée par l'IA
Comment le SaaS orienté IA utilise les agents autonomes, les flux de travail en langage naturel et l'optimisation prédictive pour accélérer les processus, réduire les coûts et intégrer